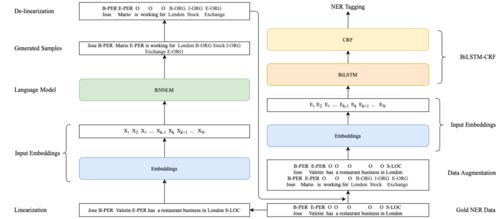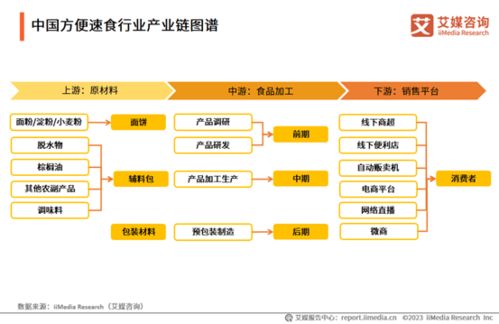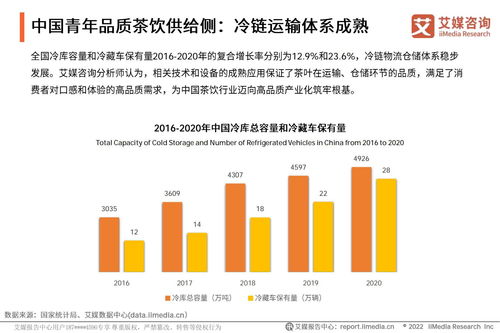
推荐系统作为连接用户与内容的关键桥梁,其核心在于通过算法模型精准预测用户兴趣。现实应用场景中,用户行为、物品属性和环境上下文往往动态变化,这就要求推荐模型具备自适应能力,以持续保持推荐效果。本文从工程实践与技术研究角度,对推荐系统中模型自适应相关技术进行梳理与总结。
一、模型自适应的核心挑战与目标
推荐系统的自适应能力主要体现在三个方面:一是应对数据分布的动态变化,如用户兴趣漂移;二是快速适应新用户、新物品的冷启动问题;三是平衡模型的稳定性与灵活性,避免因过度适应短期波动而导致长期性能下降。
二、关键技术方法梳理
1. 在线学习与增量更新
在线学习技术允许模型在接收到新数据时实时更新参数,例如基于随机梯度下降(SGD)的在线优化方法。通过增量更新,模型能够逐步适应数据流的变化,同时控制计算和存储开销。工程实践中,通常采用异步更新或小批量学习来平衡效率与效果。
2. 元学习与迁移学习
元学习通过对多个任务或场景的学习,使模型具备快速适应新任务的能力。在推荐系统中,元学习可用于解决用户或物品的冷启动问题,例如通过MAML(Model-Agnostic Meta-Learning)框架学习用户共性,从而加速个性化适配。迁移学习则通过预训练模型在新领域进行微调,实现知识迁移,例如将电商领域的用户行为模型迁移到内容推荐场景。
3. 多任务与多场景学习
在复杂推荐系统中,用户可能同时处于多个场景(如首页推荐、搜索推荐、社交推荐)。多任务学习通过共享底层表示,提升模型在不同场景下的泛化能力。同时,通过动态权重调整,模型可以自适应地关注不同任务的重要性变化。
4. 强化学习与上下文自适应
强化学习方法(如上下文多臂赌博机,Contextual Bandits)能够根据用户实时反馈调整推荐策略。通过探索与利用的平衡,模型可以自适应地优化长期收益。基于上下文的自适应技术(如时间感知模型、位置感知模型)能够结合环境动态调整推荐结果。
5. 自动化机器学习与自适应超参数优化
自动化机器学习(AutoML)技术通过自动搜索模型结构、特征工程和超参数,提升模型在变化环境中的鲁棒性。例如,基于贝叶斯优化的超参数调优能够根据在线性能动态调整学习率、正则化参数等。
三、工程实践中的关键问题
1. 数据流与系统架构
在工程层面,模型自适应通常依赖于高效的数据处理流水线,包括实时特征抽取、流式数据处理和分布式模型更新。系统架构需支持低延迟的模型推理与高吞吐的在线学习,同时保证数据一致性与系统稳定性。
2. 评估与监控
自适应性模型的评估需结合离线指标(如AUC、NDCG)与在线指标(如点击率、留存率)。通过A/B测试和多臂赌博机方法,可以实时比较不同自适应策略的效果。建立监控告警机制,及时发现模型性能漂移或数据异常。
3. 安全与稳定性
模型自适应可能引入潜在风险,如过度拟合噪声数据或被恶意攻击。工程上需通过正则化、对抗训练、异常检测等手段提升模型鲁棒性,并设计回滚机制以应对模型失效情况。
四、研究与发展趋势
当前,模型自适应技术在推荐系统中仍面临诸多挑战,包括如何在高度动态的环境中保持模型可解释性,以及如何在大规模系统中实现高效的自适应学习。未来研究方向可能集中在:
- 结合因果推理的自适应方法,以更准确地捕捉用户行为背后的因果关系;
- 联邦学习下的自适应推荐,在保护用户隐私的同时实现个性化;
- 基于大语言模型的自适应技术,利用其强大的泛化能力处理复杂推荐场景。
推荐系统中的模型自适应技术是提升系统效果与用户体验的关键。通过综合运用在线学习、元学习、强化学习等方法,并结合稳健的工程实践,能够使推荐系统在面对动态变化时保持敏捷与准确。未来的发展将更加注重自动化、安全性与可扩展性,推动推荐系统在复杂环境中持续进化。