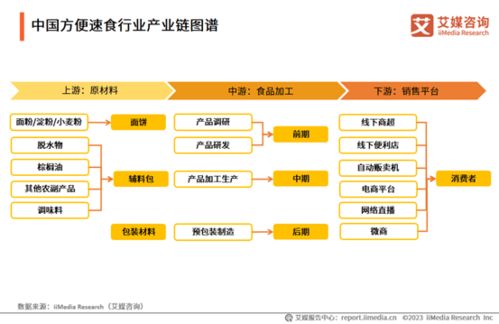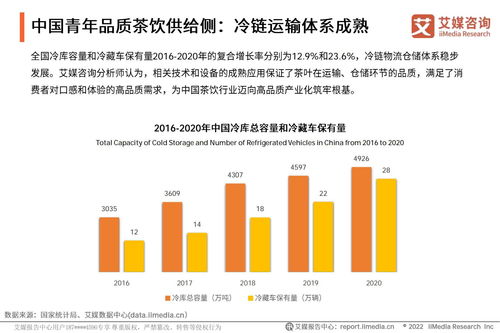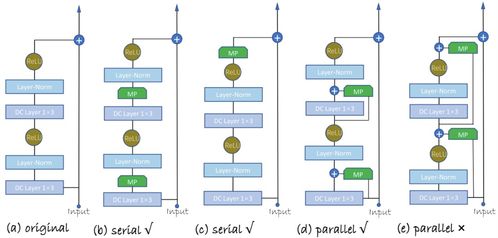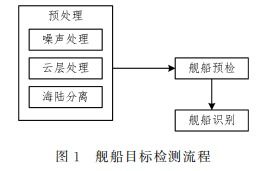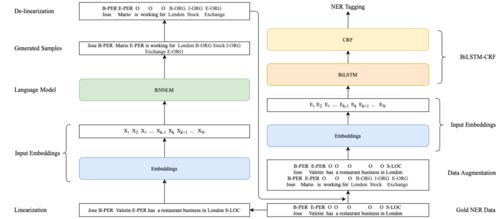
近年来,自然语言处理中的命名实体识别任务在低资源和跨语言场景下面临诸多挑战。本文聚焦于词级别数据增强技术,探讨其在工程和技术研究试验发展中的最新进展。
一、低资源与跨语言NER任务的挑战
低资源语言由于标注数据稀缺,传统监督学习方法效果受限。跨语言场景中,源语言与目标语言间的词汇、语法和语义差异进一步加剧了模型泛化困难。词级别数据增强技术通过引入同义词替换、随机插入、词序交换和字符扰动等方法,有效扩充训练数据,缓解数据不足问题。
二、词级别数据增强的核心技术
1. 基于词典的替换:利用多语言词向量或双语词典,将实体词替换为目标语言的对应词汇,保留实体边界和类型标签。
2. 随机掩码与预测:借鉴预训练语言模型思想,随机掩码部分实体词,让模型学习上下文推断实体类型。
3. 回译增强:通过多轮机器翻译生成语义一致但表达多样的训练样本,特别适用于跨语言场景。
三、工程实践与系统优化
在工程实现中,词级别数据增强需平衡生成数据的质量与多样性。研究表明,结合规则过滤和模型置信度评分可有效剔除低质量增强样本。分布式训练框架的引入加速了大规模增强数据的处理,而增量学习策略则允许模型在持续增强数据流中稳定收敛。
四、技术研究试验发展
最新研究探索了基于对抗训练的词级别增强,通过在嵌入空间添加微小扰动提升模型鲁棒性。元学习框架的引入使模型能够快速适应新语言的少量标注数据。跨语言对齐预训练模型(如XLM-R)与词级别增强的结合,在数十种低资源语言NER任务中取得了超越基线模型5-10个百分点的F1值提升。
五、未来展望
随着多模态学习和提示学习的兴起,词级别数据增强技术正与视觉-语言对齐、指令微调等新范式融合。在工程层面,自动化增强策略选择和质量评估将成为重点研究方向。这些进展将为低资源和跨语言NER任务提供更强大的技术支持,推动自然语言处理技术在全球化应用中的深度落地。